[Update 29 Nov 2017] There's a bug with the glance display feature where unlocking the phone after the glance display turns on drops the UI frame rate to 25 or so. This is super annoying. The fix is to turn off the glance display in Settings > Display > Advanced > Glance.
Camera. Hmm. So, I took the Camera2 API sample and built the basic demo camera app to explore wtf is wrong with the camera. Long story short, it's the camera driver + camera app. There are a couple of factors at play here.
First, the bundled camera app is slow to start. You can use the Footej Camera app for much faster startup and manual controls.
Second, the slow shutter speed is due to the camera driver auto-exposure liking slow shutter speeds. And maybe because rolling shutter + AC-induced light flicker makes for stripey pictures at fast shutter speeds and the AE flicker compensation goes "oo, better use a 14Hz shutter to get more even exposure in 50Hz lights".
The viewfinder is slow because it uses the AE shutter speed.
And there's no S-mode because the Camera2 API doesn't have one. There are only P and M modes.
The weirdo colors in very low light, who knows. I'll have to investigate.
And now I've got the beginnings of a camera app that works the way I like. Send money! Like, $25k. (In the words of Burnaburias: "My work in the houses of the Gods is abundant, and now I have begun an undertaking: Send much gold!")
[/Update]
Having grown more accustomed to the Nokia 8, here's the rest of the review:
- It's fast. Minimal jank (on Nougat at least). Better than the Samsung phones in that respect, they've got some UI thread resource loading stuff in the launcher that makes your first impression of the phone be "oh it's dropping frames". The Nokia's speediness is thanks to them using the Google launcher.
- The shape feels good to the hand. The bundled case has a nice feel to it. The case is very tight on the phone, it hasn't come off after dropping the phone on the floor a few times (Tho the case did crack in the corners. The phone is a-OK, thanks case.)
- I like the ringtones. The ringer volume can be set very loud, which is great outdoors.
- The camera is fine in daylight. The color profile is quite Zeiss - a sharp yellow-green with natural saturation levels and luminous whites. I guess. Could be placebo effect / just the light here.
- The camera is useless indoors. Everything's blurry, the focus is all over the place, the color balance is bananas (like, desaturated blue-green bananas veering towards gray).
- The screen's white point is very cold. 8000K+. Compared to the 6700K used on other devices, it's blue blue blue. Not good in the evening, though Oreo's Night Light helps a lot there.
2017-11-27
On CSS Modules
In our most recent project, we used React with CSS Modules. Each component had its own SASS stylesheet module in addition to the global stylesheet. This was pretty great in that I could work on one component without having to worry about my code or stylesheet changes impacting other components.
CSS Modules also cut down on merge conflicts, as we could keep the changes localised. If we had a single massive stylesheet, every time two people are styling components, there'd be a pretty big chance of a merge conflict and repo messiness. Moving to a pull request -driven workflow might work there, but it seems overkill for two-person projects.
One thing we didn't figure out was how to customize the look of a sub-component. E.g. we had a bunch of share buttons that had the same functionality but different parameters and looks. We could've made a separate component for each, but then we'd have to maintain multiple components.
In the end we went with ".shareButtons > div > a"-type CSS selectors for the share buttons. Which sucks.
I don't know if there's exists a better way. For self-written components, can always pass in props to change the styles, but for third-party components that'd be a mess. Maybe CSS Modules could adopt some Shadow DOM -style things to point inside included modules. Shadow DOM's CSS Custom Properties and inheritance -driven styling ("share-button { share-image: url(foo.jpg); color: white; }") is a bit too "here's an invisible API, have fun" to my tastes. It does get you looser coupling, but that's better done with props. For nitty-gritty styling you want to tighly couple your custom style to the component DOM because component authors can't be expected to add a custom var for every single possible style tweak. And when you do that kind of coupling, you're expected to fix it to a specific version of the component and you're visually testing it all the time anyway (I mean, that's the whole point of overriding parts of the component stylesheet).
Maybe if there was a nice way to explicitly override component stylesheets from the outside. Qualified imports? "@import('MyShareButton') as sb; sb::.container > sb::.button { letter-spacing: 0.1em; }". That ::. sure is hard to visually parse. Maybe it's a function "sb(.container) > sb(.button) {}" or "sb(.container > .button) {}" or "sb(.container { .button {} .batton {} })"?
CSS Modules also cut down on merge conflicts, as we could keep the changes localised. If we had a single massive stylesheet, every time two people are styling components, there'd be a pretty big chance of a merge conflict and repo messiness. Moving to a pull request -driven workflow might work there, but it seems overkill for two-person projects.
One thing we didn't figure out was how to customize the look of a sub-component. E.g. we had a bunch of share buttons that had the same functionality but different parameters and looks. We could've made a separate component for each, but then we'd have to maintain multiple components.
In the end we went with ".shareButtons > div > a"-type CSS selectors for the share buttons. Which sucks.
I don't know if there's exists a better way. For self-written components, can always pass in props to change the styles, but for third-party components that'd be a mess. Maybe CSS Modules could adopt some Shadow DOM -style things to point inside included modules. Shadow DOM's CSS Custom Properties and inheritance -driven styling ("share-button { share-image: url(foo.jpg); color: white; }") is a bit too "here's an invisible API, have fun" to my tastes. It does get you looser coupling, but that's better done with props. For nitty-gritty styling you want to tighly couple your custom style to the component DOM because component authors can't be expected to add a custom var for every single possible style tweak. And when you do that kind of coupling, you're expected to fix it to a specific version of the component and you're visually testing it all the time anyway (I mean, that's the whole point of overriding parts of the component stylesheet).
Maybe if there was a nice way to explicitly override component stylesheets from the outside. Qualified imports? "@import('MyShareButton') as sb; sb::.container > sb::.button { letter-spacing: 0.1em; }". That ::. sure is hard to visually parse. Maybe it's a function "sb(.container) > sb(.button) {}" or "sb(.container > .button) {}" or "sb(.container { .button {} .batton {} })"?
2017-11-10
Nokia 8 first impressions, iPhone X thoughts
[Update, Nov 26 Oreo update.] Gmail badge fixed, phone network name fixed, I can abuse the Night Light mode to tone the display white point warmer (by default it's super cold blue light: bright outdoors but eye-stabbing indoors. I've found no other way to adjust the white point but setting the Night Light mode always on (Custom Schedule 6am to 5:59am) at a low intensity.) Oreo likes to drop the UI framerate to 30fps for no reason, which is annoying. After a few minutes it jumps back to 60fps and ???? What's going on. Overheating from Night Light? Who knows, let's see if goes away after a few days... [Update 2] It's a Glance display bug. Turn off Glance display and it stops happening.
Got the tempered blue version of the Nokia 8. Around US$500 in Hong Kong. The chassis looks and feels great. The phone is very fast. Loud speaker. The LCD screen's great and shows the clock, calendar events and notifications when it's off.
The dark blue matte aluminium gets a bit smudged by fingerprints. Might be less of an issue with a silvery color - my ancient iPod Touch 5 doesn't smudge. The gold-colored iPad does smudge though. (Digression: the iPod Touch 5 is maybe the best-looking phone form factor Apple device. iPhones in comparison are marred by the antenna lines and weird design choices. Apart from the 3G, which is a great design but a bit thick. The new glass-back iPhones are better in terms of the overall design, but they're glassy.)
Back to the Nokia 8. Gmail shows a 9,999+ unread mails red badge. This is solvable, my Samsung Note 5 doesn't have that. [Fixed in the Oreo update]
In daylight, the camera quality is great. Indoors, the camera app optimizes for ISO instead of shutter speed, which makes taking photos of a bouncing six-month old an exercise in motion blur (thx 1/14 shutter speed at ISO 250.)
The camera hardware is not bad. Looking at full quality JPEG output, the noise is level is OK up to ISO 800. The camera app screws it up though.
The chassis design is generally excellent, very business-like. Might be the only phone around that doesn't look crazy. The volume and power buttons in particular look great. The shape feels good.
I've got a couple nitpicks though: the NOKIA logo on the back is recessed and looks like a sticker. It could be engraved or flush with the phone. The headphone jack doesn't have a shiny bevel and doesn't look great. The charging port might work with a bevel too. I'm not a fan of the "Designed by HMD, Made in China"-text at the back. The front face off-center Nokia logo placement is retro but grows on you. The front face fingerprint reader is recessed, which makes it gather specks of dust. Having it flush or with an Apple-style bevel would look better. The front-facing camera is a bit off-center from the hole in the face plate, and has a hard plastic looking border. This could be fixed with an alignment guide and a proper border material. Ditto for the back cameras. The front plate black plastic could maybe have a bit matte reflection so that it's not so plastic. The front speaker grille fabric gathers specks of dust. Metal mesh would be nice.
The phone appears as TA-1052 on the local network and Spotify. Which is.. confusing. [Fixed in the Oreo update]
The font on the lock screen and on the home screen clock is bolder than the glance screen font, and has a more spread out letter spacing. I prefer the glance screen thin font.
Good battery life.
Ok, that's it for the Nokia 8.
iPhone X. Played with it in the Apple Store. It works surprisingly well given the big hardware and UI overhaul. But, it's just an iPhone. Those were my thoughts, "Oh, it works surprisingly well." followed by ".. that's it?" That's really it. The software is iPhone, the identity is iPhone (with a bit of extra bling from the glass back). It's an iPhone.
The feel is quite Android though, with the bottom swipe to unlock and settings swipe down. The notch sucks in the landscape mode, looks ridiculous. The swipe gestures are invisible but quick to learn.
It's sort of like a Samsung version of the iPhone 4 in terms of the design language. Plus the notch.
The design philosophies are quite different. Samsung Note 8 is a slightly toned-down bling bling design phone. LG G6 is the techy phone searching for an identity. HTC U11 is the crazy night out phone. iPhone is the fancy party phone. Xiaomi Mi Mix 2 is the concept phone. Nokia 8 is the business phone - the dark blue two-piece suit.
Wrap up: Nokia 8 - slightly flawed execution of a great design, needs a better camera app. iPhone X - great execution of a flawed concept.
Got the tempered blue version of the Nokia 8. Around US$500 in Hong Kong. The chassis looks and feels great. The phone is very fast. Loud speaker. The LCD screen's great and shows the clock, calendar events and notifications when it's off.
The dark blue matte aluminium gets a bit smudged by fingerprints. Might be less of an issue with a silvery color - my ancient iPod Touch 5 doesn't smudge. The gold-colored iPad does smudge though. (Digression: the iPod Touch 5 is maybe the best-looking phone form factor Apple device. iPhones in comparison are marred by the antenna lines and weird design choices. Apart from the 3G, which is a great design but a bit thick. The new glass-back iPhones are better in terms of the overall design, but they're glassy.)
Back to the Nokia 8. Gmail shows a 9,999+ unread mails red badge. This is solvable, my Samsung Note 5 doesn't have that. [Fixed in the Oreo update]
In daylight, the camera quality is great. Indoors, the camera app optimizes for ISO instead of shutter speed, which makes taking photos of a bouncing six-month old an exercise in motion blur (thx 1/14 shutter speed at ISO 250.)
The camera hardware is not bad. Looking at full quality JPEG output, the noise is level is OK up to ISO 800. The camera app screws it up though.
The chassis design is generally excellent, very business-like. Might be the only phone around that doesn't look crazy. The volume and power buttons in particular look great. The shape feels good.
I've got a couple nitpicks though: the NOKIA logo on the back is recessed and looks like a sticker. It could be engraved or flush with the phone. The headphone jack doesn't have a shiny bevel and doesn't look great. The charging port might work with a bevel too. I'm not a fan of the "Designed by HMD, Made in China"-text at the back. The front face off-center Nokia logo placement is retro but grows on you. The front face fingerprint reader is recessed, which makes it gather specks of dust. Having it flush or with an Apple-style bevel would look better. The front-facing camera is a bit off-center from the hole in the face plate, and has a hard plastic looking border. This could be fixed with an alignment guide and a proper border material. Ditto for the back cameras. The front plate black plastic could maybe have a bit matte reflection so that it's not so plastic. The front speaker grille fabric gathers specks of dust. Metal mesh would be nice.
The phone appears as TA-1052 on the local network and Spotify. Which is.. confusing. [Fixed in the Oreo update]
The font on the lock screen and on the home screen clock is bolder than the glance screen font, and has a more spread out letter spacing. I prefer the glance screen thin font.
Good battery life.
Ok, that's it for the Nokia 8.
iPhone X. Played with it in the Apple Store. It works surprisingly well given the big hardware and UI overhaul. But, it's just an iPhone. Those were my thoughts, "Oh, it works surprisingly well." followed by ".. that's it?" That's really it. The software is iPhone, the identity is iPhone (with a bit of extra bling from the glass back). It's an iPhone.
The feel is quite Android though, with the bottom swipe to unlock and settings swipe down. The notch sucks in the landscape mode, looks ridiculous. The swipe gestures are invisible but quick to learn.
The design philosophies are quite different. Samsung Note 8 is a slightly toned-down bling bling design phone. LG G6 is the techy phone searching for an identity. HTC U11 is the crazy night out phone. iPhone is the fancy party phone. Xiaomi Mi Mix 2 is the concept phone. Nokia 8 is the business phone - the dark blue two-piece suit.
Wrap up: Nokia 8 - slightly flawed execution of a great design, needs a better camera app. iPhone X - great execution of a flawed concept.
2017-10-09
Ethereum algorithmically
Ethereum is a cryptocurrency with a mining process designed to stress random access memory bandwidth. The basic idea in mining Ethereum is to find a a 64-bit number that hashes with a given seed to a 64-bit number that's smaller than the target number.
Think of it like cryptographic lottery. You pick a number, hash it, and compare the hash to the target. If you got a hash that's below the target, you win 5 ETH.
What makes this difficult is the hashing function. Ethereum uses a hashing function that first expands the 32-byte seed into a 16 MB intermediate data structure using a memory-hard hashing function (if you have less than X bytes of RAM, the hash takes exponentially longer to compute), then expands the 16 MB intermediate data structure into a multi-gigabyte main data structure. Hashing a number generates a pseudo-random walk through the main data structure, where you do 64 rounds of "read 128 bytes from location X and update the hash and location X based on the read bytes."
While the computation part of the Ethereum hashing function isn't super cheap, it pales in comparison to the time spent doing random memory accesses. Here's the most expensive line in the Ethereum compute kernel: addToMix = mainDataStructure[X]. If you turn X into a constant, the hash function goes ten times faster.
Indeed, you can get a pretty accurate estimate for the mining speed of a device by taking its memory bandwidth and dividing it by 64 x 128 bytes = 8192 B.
Zo. What is one to do.
Maximize memory bandwidth. Equip every 4 kB block of RAM with a small ALU that can receive an execution state, do a bit of integer math, and pass the execution state to another compute unit. In 4 GB of RAM, you'd have a million little compute units. If it takes 100 ns to send 128 bytes + execution state from one compute unit to another, you'd get 1.28 PB/s aggregate memory bandwidth. Yep, that's over a million gigabytes per second.
With a million GB/s, you could mine ETH at 150 GH/s. At the moment, 25 MH/s of compute power nets you about $1 a day. 150 GH/s would be $6000 per day. If you can fab ten thousand of them, you'd make sixty million a day. Woooooinflation.
Think of it like cryptographic lottery. You pick a number, hash it, and compare the hash to the target. If you got a hash that's below the target, you win 5 ETH.
What makes this difficult is the hashing function. Ethereum uses a hashing function that first expands the 32-byte seed into a 16 MB intermediate data structure using a memory-hard hashing function (if you have less than X bytes of RAM, the hash takes exponentially longer to compute), then expands the 16 MB intermediate data structure into a multi-gigabyte main data structure. Hashing a number generates a pseudo-random walk through the main data structure, where you do 64 rounds of "read 128 bytes from location X and update the hash and location X based on the read bytes."
While the computation part of the Ethereum hashing function isn't super cheap, it pales in comparison to the time spent doing random memory accesses. Here's the most expensive line in the Ethereum compute kernel: addToMix = mainDataStructure[X]. If you turn X into a constant, the hash function goes ten times faster.
Indeed, you can get a pretty accurate estimate for the mining speed of a device by taking its memory bandwidth and dividing it by 64 x 128 bytes = 8192 B.
Zo. What is one to do.
Maximize memory bandwidth. Equip every 4 kB block of RAM with a small ALU that can receive an execution state, do a bit of integer math, and pass the execution state to another compute unit. In 4 GB of RAM, you'd have a million little compute units. If it takes 100 ns to send 128 bytes + execution state from one compute unit to another, you'd get 1.28 PB/s aggregate memory bandwidth. Yep, that's over a million gigabytes per second.
With a million GB/s, you could mine ETH at 150 GH/s. At the moment, 25 MH/s of compute power nets you about $1 a day. 150 GH/s would be $6000 per day. If you can fab ten thousand of them, you'd make sixty million a day. Woooooinflation.
2017-10-08
Fast marching cubes in JavaScript
Marching cubes! Where do they march? What is their tune? The name of their leader, a mystery if any.
Marching cubes works like this:
- You have a 3D array of bits and want to create a mesh out of it.
- Read a 2x2x2 cube from the array.
- Generate a mesh based on the values of the cube.
- Repeat for every 2x2x2 cube in the array and concatenate the meshes.
The individual cube meshes work like Lego blocks, they click together to form a seamless mesh.
How to do it kinda fast:
- Create cached meshes and normals for each different 2x2x2 bit cube (there are 2^8 of them). You get an array like cubeMeshes[eightBitCubeIndex].
- Create a binary array based on the original data. Unroll loops to process in chunks of 8, do it SIMD-like, pass over the original data and spit out ones and zeroes into a Uint8Array. (You could put 8 bits per byte, but it's a hassle.)
- Create a cube index Uint8Array that's going to be filled with the eight-bit cube indexes of each 2x2x2 cube in the data.
- Fill the cube index array by marching a 2x2x2 cube over the binary array and converting the read cube values into eight-bit cube indexes. Increment total mesh vertex count by cubeMeshLengths[eightBitCubeIndex].
- Allocate Float32Arrays for vertices and normals based on the total mesh vertex count.
- Iterate over the cube index array. Write the mesh corresponding to the cube index to the vertex array, offset each vertex with the xyz-coordinates of the cube index. Write the normals corresponding to the cube index to the vertex array.
Source: fastIsosurface.js - demo
This runs in ~150ms on an Intel i7 7700HQ for a 7 million element data array (256x256x109).
Future directions
As you may notice from the source, it's SIMD-friendly, in case you can use SIMD. The algorithm parallelizes easily too.
Web Workers with transferable objects? Transform feedback in WebGL 2 + a reducer kernel to remove empty triangles? Do it in a fragment shader to a float render target? Magic?
Handwaving
The test dataset contains 7 million 16-bit uints which takes about 14 megabytes of RAM. This means that it won't fit in the 7700HQ's 4x1.5MB L3 cache, much less the 4x256kB L2 or the 4x32kB L1.
By compressing the dataset into a bit array, it would fit in 7 megabits, or 875 kB. Processing that with four cores (8 threads) would keep the read operations in the L2 cache. Chunking the processing into 30 kB cubes would keep the reads mostly in the L1 cache.
The output array for the marching cubes step consists of a byte per cube. The original input array has two bytes per element. The bit array has one byte or one bit per element. The output vertex arrays have up to 90 floats, or 360 bytes per cube (but they're very sparse, the average is 1-2 bytes per cube). There's roughly one cube per input array element.
Taking the sum of the above, we get about 1 + 2 + 1 + 1 = 5 bytes per cube. We could process 6000 cubes in a 32kB L1 cache. That might come to 64x10x10 input elements that output 63x9x9 cubes for total memory use of 29406 bytes and 5103 cubes.
How fast would that be? Let's see. You need to read in the input data. That's going to come from RAM at 40 GB/s => something like 0.05 ns per cube. You can crunch it into the binary array as you go: two comparisons, a logical AND, and a store to L1 would work out to 2 ns per input element at 3GHz. For per-cube time, divide by 8 as each element is used by 8 cubes: 0.25ns per cube.
Then read through it with a 2x2x2 window for the cube generation, do a couple multiply-adds. Updating the window requires avg 4 reads per step plus processing to generate the cube indexes, say 4x7 cycles in total.
Then write the vertices to the vertex array. This might take 6 cycles for the array fetch and write.
Add some fudge, 3 GHz clock rate. Each cube takes 4x7 + 6 = 34 cycles. Estimated runtime 12ns per cube (+ 0.25ns for input data processing). Need 10 million cubes for the mesh: 120 ms. Do it in parallel in four L1 caches => 30 ms.
But, uh, it already runs in 150 ms for some meshes. And crunching the input data takes 20 ms of that. In JavaScript. What.
2017-09-23
WebGL 2.0
Started doing some vanilla WebGL 2.0 development this month. I like it. I haven't really ventured further into the new API features than doing 3D textures and GLES 3.00 shaders (which are very nice).
The new parts of the API feel a bit like this: you've got buffers and a shader program. What you do is plug the buffers into the inputs and outputs of the shader and run it. Uniforms? You can use a buffer for that. Textures? You can texImage from a buffer. After you've run your program over your vertex buffers, you can readPixels into a buffer. And there are functions for copying buffer data between buffers (and texture data from one texture to another). You can even write the vertex shader output to a buffer with transform feedback.
The fun tricks this opens up are myriad. Use a vertex shader to create a texture? Sure. Update your shader uniforms with a fragment shader? Uh ok. Generate a mesh in a fragment shader and drop it into a vertex array? Yeaaah maybe. All of this without having to read the data back into JavaScript. I wonder how far you could take that. Run an app in shaders with some interrupt mechanism to tell JavaScript to fetch the results and do something in the browserland.
There is still a dichotomy between buffers and textures, so there are some hoops to jump through if you're so inclined.
The new parts of the API feel a bit like this: you've got buffers and a shader program. What you do is plug the buffers into the inputs and outputs of the shader and run it. Uniforms? You can use a buffer for that. Textures? You can texImage from a buffer. After you've run your program over your vertex buffers, you can readPixels into a buffer. And there are functions for copying buffer data between buffers (and texture data from one texture to another). You can even write the vertex shader output to a buffer with transform feedback.
The fun tricks this opens up are myriad. Use a vertex shader to create a texture? Sure. Update your shader uniforms with a fragment shader? Uh ok. Generate a mesh in a fragment shader and drop it into a vertex array? Yeaaah maybe. All of this without having to read the data back into JavaScript. I wonder how far you could take that. Run an app in shaders with some interrupt mechanism to tell JavaScript to fetch the results and do something in the browserland.
There is still a dichotomy between buffers and textures, so there are some hoops to jump through if you're so inclined.
2017-08-24
More partial sums
Partial sums with unique input elements, for an alphabet of k elements, the time it takes to find a solution is at most 2^k, regardless of the size of the input. To flip that around, partial sums is solvable in O(n^k) where n is the size of the input and k is the size of the alphabet. Not that this does you any good, of course.
Notation duly abused.
Notation duly abused.
More on P & NP & partial sums
Another hack search problem solvable in polynomial time by a non-deterministic machine but not by a deterministic one. But it's not a proper problem. Suppose you have an infinitely large RAM of random numbers (yeah, this starts out real well). The problem is to find if an n-bit number exists in the first 2^n bits of the RAM.
As usual, the deterministic machine has to scan the RAM to find the number, taking around 2^n steps. And as usual, the non-deterministic machine just guesses the n bits of the address in n steps and passes it to checkSolution, which jumps to the address and confirms the solution. Now, this is not an NP-complete problem in this formulation, since the contents of the RAM are not specified, so there's no mapping from other NP-complete problems to this.
Jeez, random numbers.
Given the lottery numbers for this week's lottery, compute the lottery numbers for next week's lottery. Non-deterministic machine: sure thing, done, bam. Deterministic machine: this might take a while (btw, is simulating the universe a O(n^k)-problem?) Check solution by checking bank account.
Unique inputs partial sums then. First off, sort the inputs, and treat them as a binary number where 0 is "not in solution" and 1 is "in solution".
If all the numbers in the input are such that the sum of all smaller inputs is smaller than the number, you can find the solution in linear time. For (i = input.length-1 to 0) { if (input[i] <= target) { target_bits[i] = 1; target -= input[i]; } else { target_bits[i] = 0; }}
You can prune the search space by finding a suffix that's larger than the target and by finding a prefix that's smaller than the target. Now you know that there must be at least one 0-bit in the larger suffix and at least one 1-bit in the suffix of the smaller prefix.
The time complexity of partial sums is always smaller than 2^n. For a one-bit alphabet, the time complexity is O(n). For a two-bit alphabet, the max time complexity is 2^(n/2) as you need to add two bits to the input to increment the number of elements in the input. So for an 8-bit alphabet, the max complexity would be 2^(n/8).
The complexity of partial sums approaches easy as the number of input elements approaches the size of the input alphabet. After reaching the size of the input alphabet, a solution exists if (2^a + 1) * (2^a / 2) <= target (as in, if the sum of the input alphabet is greater than or equal to target. And if the input alphabet is a dense enumeration up from 1.) You can find the solution in O(n log n): sort input, start iterating from largest & deduct from the target until the current number is larger than the target. Then jump to input[target] to get the last number. You can also do this in O(n) by first figuring out what numbers you need and then collecting them from the input with if (required_numbers[input[i]]) pick(input[i]), required_numbers can be an array of size n.
Once you reach the saturated alphabet state, you need to increase the size of the alphabet to gain complexity. So you might go from an 8-bit alphabet with a 256 element input to a 9-bit alphabet with a 256 element input (jumping from 2048 to 2304 bits in the process, hopefully boosting the complexity from O(256)-ish to O(2^256)-ish).
Thankfully, as you increase the alphabet size by a bit, your input size goes up linearly, but the saturation point of your alphabet doubles. At a fixed input size in bits, increasing the alphabet size can decrease the complexity of the problem, for each bit increase you can go from 2^(n/k) -> 2^(n/(k+1)). Likewise, by decreasing the alphabet size, you can increase the complexity of the problem. Increasing the number of elements in the input can increase the complexity of the problem, while decreasing the number of elements can decrease the complexity. The "can" is because it depends. If you're close to saturation, increasing the number of elements can nudge the problem from O(n^2) to O(n), ditto for decreasing the alphabet size. Whereas increasing the alphabet size at saturation can turn your O(n) problem into an O(2^n) problem.
As your alphabet gets larger, the discontinuities stop being so important. Anyhow, for a given partial sums input size in bits, the problem is O(n) for alphabet sizes <= log2(n). The difficulty of the problem scales with the target as well. For targets smaller than the smallest input element and for targets greater than the greatest input element, it takes O(n) time.
Tricks, hmm, the number of search-enhancing tricks you can use depends on the input. I guess the number of tricks is somehow related to the number of bits in the input and grows the program size too. The ultimate trick machine knows all the answers based on the input and has to do zero extra computation (yeah, this is the array of answers), but it's huge in size and requires you to solve the problem for all the inputs to actually write the program.
Oh well
As usual, the deterministic machine has to scan the RAM to find the number, taking around 2^n steps. And as usual, the non-deterministic machine just guesses the n bits of the address in n steps and passes it to checkSolution, which jumps to the address and confirms the solution. Now, this is not an NP-complete problem in this formulation, since the contents of the RAM are not specified, so there's no mapping from other NP-complete problems to this.
Jeez, random numbers.
Given the lottery numbers for this week's lottery, compute the lottery numbers for next week's lottery. Non-deterministic machine: sure thing, done, bam. Deterministic machine: this might take a while (btw, is simulating the universe a O(n^k)-problem?) Check solution by checking bank account.
Unique inputs partial sums then. First off, sort the inputs, and treat them as a binary number where 0 is "not in solution" and 1 is "in solution".
If all the numbers in the input are such that the sum of all smaller inputs is smaller than the number, you can find the solution in linear time. For (i = input.length-1 to 0) { if (input[i] <= target) { target_bits[i] = 1; target -= input[i]; } else { target_bits[i] = 0; }}
You can prune the search space by finding a suffix that's larger than the target and by finding a prefix that's smaller than the target. Now you know that there must be at least one 0-bit in the larger suffix and at least one 1-bit in the suffix of the smaller prefix.
The time complexity of partial sums is always smaller than 2^n. For a one-bit alphabet, the time complexity is O(n). For a two-bit alphabet, the max time complexity is 2^(n/2) as you need to add two bits to the input to increment the number of elements in the input. So for an 8-bit alphabet, the max complexity would be 2^(n/8).
The complexity of partial sums approaches easy as the number of input elements approaches the size of the input alphabet. After reaching the size of the input alphabet, a solution exists if (2^a + 1) * (2^a / 2) <= target (as in, if the sum of the input alphabet is greater than or equal to target. And if the input alphabet is a dense enumeration up from 1.) You can find the solution in O(n log n): sort input, start iterating from largest & deduct from the target until the current number is larger than the target. Then jump to input[target] to get the last number. You can also do this in O(n) by first figuring out what numbers you need and then collecting them from the input with if (required_numbers[input[i]]) pick(input[i]), required_numbers can be an array of size n.
Once you reach the saturated alphabet state, you need to increase the size of the alphabet to gain complexity. So you might go from an 8-bit alphabet with a 256 element input to a 9-bit alphabet with a 256 element input (jumping from 2048 to 2304 bits in the process, hopefully boosting the complexity from O(256)-ish to O(2^256)-ish).
Thankfully, as you increase the alphabet size by a bit, your input size goes up linearly, but the saturation point of your alphabet doubles. At a fixed input size in bits, increasing the alphabet size can decrease the complexity of the problem, for each bit increase you can go from 2^(n/k) -> 2^(n/(k+1)). Likewise, by decreasing the alphabet size, you can increase the complexity of the problem. Increasing the number of elements in the input can increase the complexity of the problem, while decreasing the number of elements can decrease the complexity. The "can" is because it depends. If you're close to saturation, increasing the number of elements can nudge the problem from O(n^2) to O(n), ditto for decreasing the alphabet size. Whereas increasing the alphabet size at saturation can turn your O(n) problem into an O(2^n) problem.
As your alphabet gets larger, the discontinuities stop being so important. Anyhow, for a given partial sums input size in bits, the problem is O(n) for alphabet sizes <= log2(n). The difficulty of the problem scales with the target as well. For targets smaller than the smallest input element and for targets greater than the greatest input element, it takes O(n) time.
Tricks, hmm, the number of search-enhancing tricks you can use depends on the input. I guess the number of tricks is somehow related to the number of bits in the input and grows the program size too. The ultimate trick machine knows all the answers based on the input and has to do zero extra computation (yeah, this is the array of answers), but it's huge in size and requires you to solve the problem for all the inputs to actually write the program.
Oh well
2017-08-22
Tricks with non-determinism. Also, partial sums.
TL;DR: I've got a lot of free time.
Non-deterministic machines are funny. Did you know that you can solve any problem in O(size of the output) with a non-deterministic machine? It's simple. First, enumerate the solution space so that each possible solution can be mapped to a unique string of bits. Then, generate all bitstrings in the solution space and pick the correct solution.
Using a deterministic machine, this would run in O(size of the solution space * time to check a solution). In pseudocode, for n-bit solution space: for (i = 0 to 2^n) { if(checkSolution(i)) { return i; } } return NoSolution;
Using a non-deterministic machine, we get to cheat. Instead of iterating through the solution space, we iterate through the bits of the output, using non-determinism to pick the right bit for our solution. In pseudocode: solution = Empty; for (i = 0 to n) { solution = setBit(solution, i, 0) or solution = setBit(solution, i, 1); } if (checkSolution(solution)) { return solution; } else { return NoSolution; }
You can simulate this magical non-deterministic machine using parallelism. On every 'or'-statement, you spawn an extra worker. In the end you're running a worker on every possible solution in parallel, which is going to run in O(N + checkSolution(N))-time, where N is the number of bits in the solution.
If you're willing to do a bit more cheating, you can run it in O(checkSolution(N))-time by forgoing the for-loop and putting every solution into your 'or'-statement: solution = 0 or solution = 1 or ... or solution = 2^N; if (checkSolution(solution)) { return solution; } else { return NoSolution; }. If you apply the sleight-of-hand that writing out the solution as input to checkSolution takes only one step, this'll run in checkSolution(N). If you insist that passing the solution bits to checkSolution takes N steps, then you're stuck at O(N + checkSolution(N)).
A deterministic machine could cheat as well. Suppose that your program has been specially designed for a single input and to solve the problem for that input it just has to write out the solution bits and pass them to checkSolution. This would also run in N + checkSolution(N) time. But suppose you have two different inputs with different solutions? Now you're going to need a conditional jump: if the input is A, write out the solution to A, otherwise jump to write the solution to B. If you say that processing this conditional is going to take time, then the deterministic machine is going to take more time than the non-deterministic one if it needs to solve more than one problem.
What if you want the deterministic machine to solve several different problems? You could cheat a bit more and program each different input and its solution into the machine. When you're faced with a problem, you treat its bitstring representation as an index to the array of solutions. Now you can solve any of the problems you've encoded into the program in linear time, at the expense of requiring a program that covers the entire input space. (Well, linear time if you consider jumps to take constant time. If your jumps are linear in time to their distance... say you've got a program of size 2^N and a flat distribution of jump targets over the program. The jumps required to arrive at an answer would take 2^(N-1) time on average.)
Note that the program-as-an-array-of-solutions approach has a maximum length of input that it knows about. If you increase the size of your input, you're going to need a new program.
How much of the solution space does a deterministic machine need to check to find a solution? If we have a "guess a number"-problem, where there's only one point in the solution space that is the solution, you might assume that we do need to iterate over the entire space to find it in the worst case. And that would be true if checkSolution didn't contain any information about the solution. In the "guess a number"-problem though, checkSolution contains the entire answer, and you can solve the problem by reading the source to checkSolution.
Even in a problem like partial sums (given a bunch of numbers, does any subset of them sum to zero; or put otherwise: given a bunch of positive numbers, does any combination sum to a given target number), the structure of the problem narrows down the solution space first from n^Inf to n! (can't pick the same number twice), then to 2^n (ordering doesn't matter) and then further to 2^n-n-1 (an answer needs to pick at least two elements), and perhaps even further, e.g. if the first number you pick is even, you can narrow down its solution subtree to combinations of even numbers and pairs of odd numbers. Each number in the input gives you some information based on the structure of the problem.
The big question is how fast the information gain grows with the size of the input. That is, suppose your input size is n and the solution space size is 2^n. If you gain (n-k) bits of solution from the input, you've narrowed the solution space down to 2^(n-(n-k)) = 2^k. If you gain n/2 bits, your solution space becomes 2^(n/2). What you need to gain is a magical number that plonks exp(f(n)) <= k n^(k-1). If there is such an f(n), you can find a solution to your problem in polynomial time.
If your input and checkSolution are black boxes, you can say that a deterministic machine needs to iterate the entire solution space. If checkSolution is a black box, you can do the "guess a number"-problem. If your input is also a black box, you can't use partial solutions to narrow down the solution space. For example, in the partial sums problem, if you only know that you've picked the first and the seventh number, but you don't know anything about them, you can only know if you have a solution by running checkSolution on your picks. If you can't get any extra information out of checkSolution either, you're stuck generating 2^n solutions to find a match.
How about attacking the solution space of partial sums. Is the entire solution space strictly necessary? Could we do away with parts of it? You've got 2^n-n-1 different partial sums in your solution space. Do we need them all? Maybe you've got a sequence like [1,2,-3,6], that's got some redundancy: 1+2 = 3 and -3+6 = 3, so we've got 3 represented twice. So we wouldn't have to fill in the entire solution space and could get away with generating only parts of it for any given input? Not so fast. Suppose you construct an input where every entry is double the size of the previous one: e.g. [1,2,4,8,16, ...]. Now there are 2^n-1 unique partial sums, as the entries each encode a different bit and the partial sums end up being the numbers from 1 to 2^n-1.
But hey, that sequence of positive numbers is never going to add up to zero, and the first negative number smaller than 2^n is going to create an easy solution, as we can sort the input and pick the bits we need to match the negative number. Right. How about [1, -2, 4, -8, 16, -32, ...]? That sequence generates partial sums that constitute all positive numbers and all negative numbers, but there is no partial sum that adds up to zero, and no partial sum is repeated. If your algorithm is given a sequence like this and it doesn't detect it, it'll see a pretty dense partial sum space of unique numbers that can potentially add up to zero. And each added number in the input doubles the size of the partial sum space.
Can you detect these kinds of sequences? Sort the numbers by their absolute value and look for a sequence where the magnitude at least doubles after each step. Right. What if you use a higher magnitude step than doubling and insert one less-than-double number into the sequence in a way such that the new number doesn't sum up to zero with anything? You'll still have 2^n unique partial sums, but now the program needs to detect another trick to avoid having to search the entire solution space.
If the input starts with the length of the input, the non-deterministic machine can ignore the rest of the input and start generating its solutions right away (its solutions are bitstrings where e.g. for partial sums a 1 means "use this input in the sum" and a 0 means "skip this input"). The deterministic machine has to read in the input to process it. If the input elements grow in size exponentially, the deterministic machine would take exponentially longer time to read each input. Suppose further that the possible solution to the problem consists of single digit numbers separated by exponentially large inputs and that jumping to a given input takes a constant amount of time (this is the iffy bit). Now the non-deterministic machine still generates solutions in linear time, and checkSolution only has to deal with small numbers that can be read in quickly, but the deterministic machine is stuck slogging through exponentially growing inputs.
You might construct a magical deterministic machine that knows where the small numbers are, and can jump to consider only those in its solution. But if you want to use it on multiple different inputs, you need to do something different. How about reading the inputs one bit at a time and trying to solve the problem using the inputs that have finished reading. Now you'll get the small numbers read in quickly, find the solution, and finish without having to consider the huge inputs.
If the solution uses one of the huge inputs, checkSolution would have to read it in and become exponential. Or would it? Let's make a padded version of the partial sums problem, where the input is an array of numbers, each consisting of input length in bits, payload length in bits, and the payload number padded with a variable-size prefix and suffix of zeroes and a 1 on each end, e.g. you could have {16, 3, 0000 0101 1100 0000} to encode 011. The checkSolution here would take the index of the number in the input array and size of its prefix. This way checkSolution can extract and verify the padded number with a single jump.
Now, the deterministic machine would have to search through the input to find a one-bit, using which it could then extract the actual number encoded in the input. For exponentially growing inputs, this would take exponential time. The non-deterministic machine can find the input limits quickly: for (i = 0 to ceil(log2(input_bitlength))) { index_bits[i] |= 1 or 0 }. The non-deterministic machine can then pass the generated indices alongside with the generated partial sum permutation to checkSolution, which can verify the answer by extracting the numbers at the given indices and doing the partial sum.
Approaching it from the other direction, we can make a program that generates an exponential-size output for a given input. Let's say the problem is "given two numbers A and B, print out a string of length 2^(2^A), followed by the number B." Now (if jumps are constant time), checkSolution can check the solution by jumping ahead 2^(2^A) elements in the output, reading the rest and comparing with B. You can imagine a non-deterministic machine with infinite 'or'-statements to generate all strings (which by definition includes all strings of length 2^(2^A) followed by the number B.) The problem is that if writing any number of elements to checkSolution is free, the deterministic machine could also check A, execute a single command to write 2^(2^A) zeroes to checkSolution and another to append the number B. If there is no free "write N zeroes"-loophole in the machine, and it must generate the string of zeroes by concatenating strings (let's say concatenating two strings takes 1 step of time), we've got a different case. Start off with a string of length 1, concatenate it with itself and you have 2, repeat for 4, etc. To get to a string of length 2^(2^A), you need to do this 2^A times.
But hey, doesn't checkSolution have to generate the number 2^(2^A) too to jump to it? And doesn't that take 2^A time? You could pass it that, sure, but how can it trust it? If checkSolution knows the length of its input (through some magic), it could jump to the end of it and then the length of B backwards. But it still needs to check that the length of its input is 2^(2^A) + length(B). If you were to use 2^A instead of 2^(2^A), you could make this work if string creation needs one time step per bit. (And again, if passing a solution to checkSolution takes no time.)
So maybe you set some limits. The machines need to be polynomial in size to input, and they need to have a polynomial number of 'or'-statements. Jumps cost one time step per bit. Passing information to checkSolution takes time linear to the length of the info. You have access to checkSolution and can use it to write your machine. Each machine needs to read in the input before it can start generating a solution.
What's the intuition? Partial sums takes an input of size n and expands it to a solution space of 2^n, and the question is if you can compress that down to a solution space of size n^k (where n^k < 2^n for some n). A naive enumeration of the solution space extracts 0 bits of solution information from the input, hence takes 2^n steps but is small in size. A fully informed program can extract full solution information from the input (since the input is basically an array index to an array of answers), but requires storing the entire 2^n solution space in the program. Is there a compression algorithm that crunches the 2^n solution space down to n^k size and extracts a solution in n^m steps?
Partial sums is a bit funny. For fixed-size input elements that are x bits long, and a restriction that the input can't have an element multiple times, partial sums approaches linear time as the number of input elements approaches 2^x. If the input contains every different x-bit number, it can generate all the numbers up to the sum of its input elements (i.e. the input defines a full coverage over the codomain). In fact, if the input contains every one-bit number up to n bits, you can generate every number n bits long.
The time complexity of unique set partial sums starts from O(n) at n=1 and ends up at O(n) at n=2^n. (Or rather, the time complexity is O(n) when n equals the size of the input alphabet.) It feels like the complexity of partial sums on a given alphabet is a function that starts from O(n) and ends at O(n) and has up to O(2^n) in the middle.) There's an additional bunch of O(n) solutions available for cases where the input includes all one-bit numbers up to 2^ceil(log2(target)). And a bunch of O(n log n) solutions for cases where there's a 2-element sum that hits target (keep hashtable of numbers in input, see if it contains target - input[i]). And for the cases where there are disjoint two-element sums that generate all the one-bit numbers for the target.
The partial sums generated by an input have some structure that can be used to speed up the solution in a general case. If you sum up all the numbers in the input, you generate the maximum sum. Now you can remove elements from the max sum to search for the target number from above and below. With the two-directional search, the difficult target region becomes partial sums that include half of the input elements. There are n choose n/2 half sums for an input of size n. The derivative of n choose n/2 approaches 2 as n increases, doubling the number of half sums on each step in input size.
You can also start searching from the target number. Add numbers to the target and try to reach max sum and you know which numbers you need to subtract from max sum to make up the target. Subtract numbers from the target and try to reach one of the inputs to find the numbers that make up the target.
Combining the two approaches. If you think of this thing as a binary number with one bit for each input element, on/off based on whether the element is in the solution. The bottom search runs from all zeroes, turning on bits. The max sum search runs from all ones, turning bits off. The from-target searches run from all zeroes and all ones, turning bits on or off respectively.
There is an approach for rejecting portions of the search space because they sum to a number higher than the target. Sort the input by magnitude, sum up the high end until the sum is larger than the target. Now you can reject the portion of the search space with that many top bits set. As the attacker, you want to craft a target and an input such that the search algorithm can reject as little of the search space as possible, up to the half sums region. However, this creates a denser enumeration in the half sums region, which makes clever search strategies more effective (e.g. suppose you have numbers from 1 to 4: now you know that you can create any number up to 10 out of them.)
To make the input hard, you should make the target higher than the largest number in the input, but small enough that it doesn't require the largest number in the input, the target should require half of the input elements, the input elements should avoid dense enumerations, one-bit numbers, partial sums that add up to one-bit numbers, disjoint bit patterns (and disjoint complements), the number of input elements should be small compared to the input alphabet, and they should be widely distributed while remaining close to target / n (hah). Your inputs should probably be co-prime too. And you should do this all in a way that doesn't narrow the search space to "the top hardest way to build the target number out of these inputs".
For repeated number partial sums, if your input alphabet size is two, it runs in O(n), as the partial sums of zeroes and ones is a dense enumeration up to the number of ones in your input. For other repeated sums, it's difficult. Maybe you could think of them as modulo groups. And somehow make them work like uniques time-complexity-wise.
The trouble in partial sums are carries. If you change the problem to "does the binary OR of a subset of the input elements equal the target", the problem becomes easier "for all bits in the target, find an input that has that bit and none of the bits in the target's complement", which turns into target_check_bits[i] |= input[x][i] & !(input[x] & !target).
Once you throw in the carries, suddenly there are multiple ways to produce any given bit. If you know that there are no carries in the input (that is, each bit appears only once in the input), the problem turns into the binary OR problem.
2017-08-04
Acceleration, 3
Oh right, right, I was working on this. Or something like this. Technology research post again :(
First I was working on this JavaScript ray tracer with BVH acceleration and voxel grid acceleration. And managed to get a 870k dragon loaded into it and rendered in less than 30 seconds... In quite unoptimized single-threaded JavaScript.

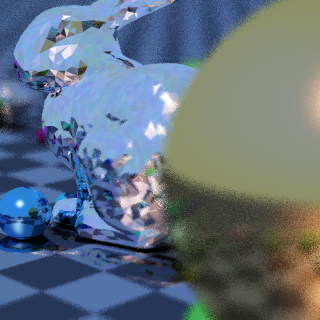




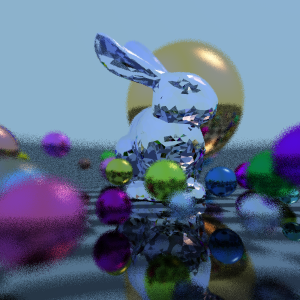

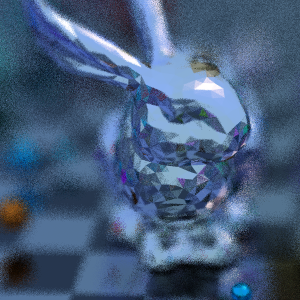


Then I had an idea and spent two weeks doing noise-free single-sample bidirectional path tracing. But it turns the high-frequency noise into low-frequency noise and runs too slow for realtime. I'll have to experiment more with the idea. Shadertoy here. Start with the writeup and screenshots after that.












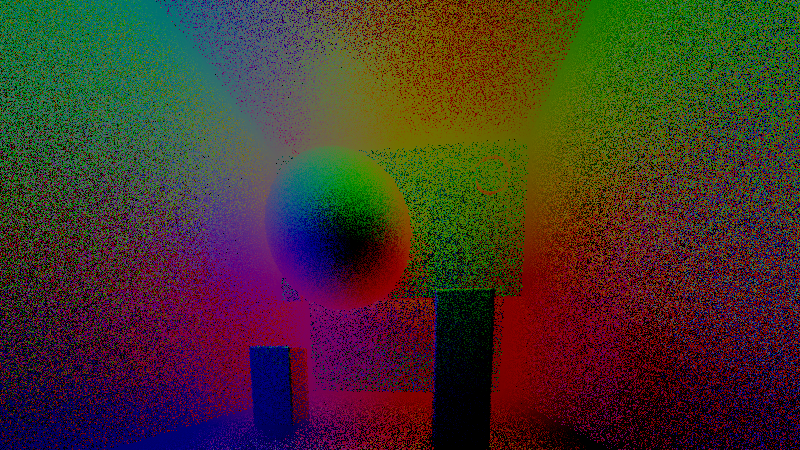







First I was working on this JavaScript ray tracer with BVH acceleration and voxel grid acceleration. And managed to get a 870k dragon loaded into it and rendered in less than 30 seconds... In quite unoptimized single-threaded JavaScript.
Then I had an idea and spent two weeks doing noise-free single-sample bidirectional path tracing. But it turns the high-frequency noise into low-frequency noise and runs too slow for realtime. I'll have to experiment more with the idea. Shadertoy here. Start with the writeup and screenshots after that.
Single-sample bidirectional path tracing + hemisphere approximation
Smooth indirect illumination by creating the incoming light hemisphere on the fly
based on the hemisphere samples of the surrounding pixels.
See also: Virtual point lights, bidirectional instant radiosity
First pass: Create path suffixes = point with incoming ray of light.
1. Shoot out primary ray and bounce it off the hit surface.
2. Trace the first bounce and store its hit point, normal and material.
3. Trace the rest of the path from the first bounce point and store the direction of the path.
4. Store the amount of light at the first bounce point.
Now you have a path suffix at each pixel that has enough info to connect any other path to it.
Second pass: Connect the primary ray to path suffixes in surrounding pixels.
1. Shoot out primary ray and calculate direct light for it
2. Sample NxN samples around the pixel from the path suffix buffer
3. Accumulate the light from the hemisphere. For each sample:
3.1. Calculate the direction to it: hd = normalize(sample.p - primary.p)
3.2. Accumulate light according to the BRDFs of the primary point and the hemisphere point.
[3.3. Scale the light contribution with a pixel distance filter for smoother transitions]
Extra passes: Create new path suffixes by connecting points in path suffix buffer to other path suffixes
1. Primary ray hits can act as path suffixes for hemisphere points (and have nice geometric connection at same px coord).
2. Hemisphere points can act as path suffixes for hemisphere points (but may lie on the same plane near px coord).
3. Add light from new path suffixes to primary hits.
Why this might be nice?
- Get more mileage from paths: in scenes with difficult lighting conditions, the chances of
finding light are low for any given path. By summing up the contributions of 10000 paths,
you've got a much higher chance of finding light for a pixel.
- Less noise: noise is variance in hemisphere sampling. If neighbouring pixels have similar
hemispheres, there's smooth variance and little noise.
- If you have the budget, you can cast shadow rays to each hemisphere point and get correct lighting.
- If you don't have the budget, you can use the hemi points as soft light and get blurry lighting
- You can use the found hemisphere light to approximate a point's light distribution and guide your sampler.
- You can use light samples from previous frames.
What sucks?
- If you don't cast shadow rays, you get light bleeding and everything's blurry.
- Casting 1000 shadow rays per pixel is going to have an impact on performance
- Direct lighting remains noisy
(you can use direct light as a hemisphere sample but it causes even more light bleeding w/o shadow rays)
- This scene smooths out at 64x64 hemisphere samples per pixel, which is expensive to sample
- Increasing the size of your sampling kernel increases inaccuracies w/o shadow rays
- It seems like you trade high-frequency noise for low-frequency noise
- Glossy stuff is hard
The ugly:
- Using three buffers to trace because no MRTs, otherwise could store hemi hit, normal, dir, primary hit,
hemi color, primary color on a single trace, and recombine on the second pass.
- Slow SDF ray marcher as the rendering engine
- Not storing incoming light dir atm, all the lighting equations are hacks in this demo
2017-07-14
Acceleration, 2
Oh, yeah, right. I was working on this.
But got distracted by adding features to my path tracing Shadertoy. So. I've got pictures if nothing else. Pictures of the same scene to test bidirectional path tracing, bokeh, diffraction, etc. There you go.
Tune in next week for more of .. something?












2017-07-03
Acceleration, 1

Working on Acceleration.
It's not fast going, but it's going bit by bit. I currently have some color pickers, auto-keyframing, save, load, hi(gher)-quality still render creation, on top of the very visual-oriented animation editor. There used to be a 4-view for moving things about but that felt clunky and the shader implementation wasn't great, so it's dormant for now.
Now I've been working on two workstreams: 1) event handling dataflow graph and 2) rendering research. Rendering research is going towards, uh, realtime bi-directional path tracing. Which might kill the whole thing due to "I don't know how to make an acceleration structure for triangle models", but at least I'll get cool screenshots out of it.

Event handling dataflow graph. It's one of those things. You know. You think that it'll just be some "on click, set variable Y to 20"-thing. And then you think about it and end up with some sort of loosely bound lazily evaluated array language execution graph with a query language to select objects. And then you start thinking "How would I build shaders with this?", "Could you run this in parallel?", "Should I compile this down into WebAssembly?"
In a word: utmost care must be taken to avoid rabbit holes that lead to endless destruction in the fiery magma caves under the Earth's crust.

Anyway. The event graph nodes. To execute a node, you first evaluate all its inputs. To evaluate an input, you need to find the object referred by the input object and resolve its value. Why? Passing objects by reference feels brittle. Like. If I've got a node with an input and I want to pass that input to another node (say, I want to modify the scale of the clicked object: OnClick(obj) -> ModifyScale(obj)). If I pass it by reference, the two nodes need to point to the same object. When OnClick's input's value changes, ModifyScale's input's value needs to change as well. And how do you draw it? How do you draw a line from OnClick's input to ModifyScale's input? You need to know that they are the same object, referred to from two different places, and figure out the coordinates for those two places. So a value needs to carry a reference to its render model, so that you can figure out where it's located. Or the value can be defined as a loosely bound address that's resolved at runtime "OnClick.inputs.Object" -> obj = graph.objects["OnClick"]; input = obj.inputs["Object"]; point = obj.renderModel.inputs["Object"].connectorPoint;.
Node {
renderModel: Model,
func: Function,
inputs: {string: Value, ...},
outputs: {string: Value, ...},
futures: [Node] // array because if-then-else/switch-statements
futureIndex: int // which future to follow
}
Maybe this is .. workable?
On the rendering research side of things, considering a few options. SDFs? Raytraced geometry? Simple primitives and/or triangle soup? Path tracing with a procedural environment map as the main light source? In real-time? Progressive renderer for high-quality stills. HTML elements overlaid on top of the 3D scene. Fancy SDF text that scales to millions of letters in realtime? 3D text meshes? Images, video, particles, what? What's the goal here? Build animations in 15 minutes. Make animation timelines that compose. Renderer to make cool-looking interactives with a unique look.

Right. Anyhow, rendering goals: nice motion blur, shiny CG look, high-quality stills, depth-of-field, glowy blooms, volumetrics. All of which point towards: "just path trace it". It'll impose definite limitations on the scenes that work alright on it. Maybe that's fine? The underlying timeline + event graph stuff should be generic enough to plug in a Three.js renderer. I wonder about the transformation widgets, animation 3D paths, and other "way easier to rasterize"-stuff though. So, rasterize those on top of the scene. The path tracer can write to depth buffer with the primary rays too. Hybrid renderer!

It's complex. Do it piece by piece. Make it simpler until it's possible.
Part 2 on 10th of July. Goals: event graph prototype working.

2017-04-16
Electrostatic fluid accelerator
Imagine a fan with no moving parts. Instead of using spinning blades to push air molecules around, you use ions accelerated by an electric field. This, in a nutshell, is an electrostatic fluid accelerator.
(Thinking of the Dyson fans that create a thin high-velocity flow to entrain a larger air volume and pull it along. Now they have a small fan at the bottom to push air through the exhaust. Which makes a whirring noise. What if you replaced the fan with an electrostatic fluid accelerator set around the exhaust.)
(Thinking of the Dyson fans that create a thin high-velocity flow to entrain a larger air volume and pull it along. Now they have a small fan at the bottom to push air through the exhaust. Which makes a whirring noise. What if you replaced the fan with an electrostatic fluid accelerator set around the exhaust.)
2017-04-09
Engineering antibiotic-suspectible strains of bacteria
Make antibiotic resistance into a detriment. Petri dish with antibiotic gradient. Radiation steriliser at the high antibiotic section. Microbes that survive in the antibiotic get killed by the radiation. Microbes without resistance survive and supplant the resistant strain.
2017-03-16
Latest 8 rumors
8 is going to have three cameras on the back. One with a 16-35 mm equivalent lens, one with a 24-70 mm lens, and a third one with a 70-200 mm lens.
8 uses the input from each of the lenses to stabilize images. The images you see on the 8 screen are going to be extremely stable. By integrating the optical flow from the cameras with the accelerometer readings and the pupil tracking from the forward-facing selfie cam, 8 can make the text you're reading compensate for the motion of the phone, so that the text appears stable and readable even when you're out running. The 8 also compensates for the distance of the phone from your eyes by increasing text size when the phone is further away. With computational reconvolution algorithms and advanced glasses-detecting computer vision techniques, the 8 can re-focus the phone screen so that no matter you're wearing your glasses or not, the 8 looks 20/20.
8 comes with an extendable screen. By using the side-mounted magnetic connectors, you can clip several 8 devices together to expand the size of your screen as far and wide as you want. The UI automatically expands to fill all available devices and switches from phone mode to tablet mode to PC mode to TV mode as the screen grows.
8 has three pico-projectors: one on the back and two in the front. The projector on the back of the phone creates an interactive tablet surface. The image is projected by the projector, and the back cameras can track your hands to make a virtual touch screen. The camera sees the color and the shape of the surface you're projecting on, automatically correcting the colors and the shape of the projection so that the image appears in the right colors and the right shape. You can use the back projector to play Kinect-style games on the wall, watch movies off the seat in front of you, display photos and documents on the meeting room desk. The front projectors track your pupils and plunge you into glassless virtual reality. The front projectors are also used to project a selfie-boosting projection field on your face that smooths out your skin, eliminates wrinkles, enlarges your eyes and slims your cheeks.
8 has 4 GB of HBM2 RAM stacked on top of a heterogenous processing die, composed of a single 4 GHz core, three 1.5 GHz cores, and 128 tiny graphics cores running at 1 GHz. The total bandwidth available for the computing cores is 256GB/s, and they can crank out 1.1 TFLOPS (single precision, ARM NEON 128-bit fused mul-add), in an address space shared between all the cores. Backing the compute cores is a two-level storage subsystem with 256 GB Flash providing 2.5 GB/s bandwidth, and a high-speed 4GB DDR pre-populated cache in front of it, serving frequently accessed data at 20 GB/s. The 8 has a lot of numbers. It comes with a worksheet-style calculator to help you manage them.
8 comes with a deep learning AI stack, used by the 8 to help manage your life. From simple things like running a spam filter on your notifications, to advanced life management techniques for building high-productive schedules, writing emails faster, researching projects and keeping you fit, the 8 puts a whole team of AI assistants at your service. With the Fake News Blocker built into the 8 browser, you won't be hoodwinked by rogue AIs and shady operators. With the 8 Scalable Helper assistant, you can provide a fully automated AI service to others and get paid for each Bit of Assistance provided.
The AI assistant team makes you a full member in today's society. With its Opinion Optimizer feature – it summons a hard-working team of virtual commenters who take your side – you can participate in online discussions as an equal opponent to other fully-armed members of the sociosphere. In case you need that extra bit of help persuading someone, the News Dreamer feature comes fully equipped with all the latest news-generating systems. Late from work? No problem! The News Dreamer can create A/B tested news stories about traffic jams and bridge closures, ready to be presented as alternative facts.
Another exciting feature of the 8 is the built-in Government app. The Government app polls you daily for your input on matters local and global. By participating in the Government, you help discover issues, find solutions for them and take part in implementing the solutions.
By buying the 8, you become a shareholder in the company that runs the Government and the Scalable Helper. As a shareholder, you'll receive a quarterly dividend from the profits generated by the company.
8 has a scan button on its side. By pressing the scan button, the camera view pops up on the screen. With the scan app, you can read QR codes, pay bills, scan business cards, save notes, translate text, see navigation directions overlaid on the view, and pull up information about the things you see. If a QR code is a link to a 3D object, the scan app loads in the object and shows it in augmented reality. You can also use the scan app to contribute information about the things that you see.
The 8 has wireless charging. Using beamforming, the charger aims a supercharged WiFi signal at the 8 with enough power to charge it. While not as fast as cable charging, the wireless charger can top the 8 to full charge in around 4 hours, and works anywhere in a 5 meter radius to the charger.
8 uses the input from each of the lenses to stabilize images. The images you see on the 8 screen are going to be extremely stable. By integrating the optical flow from the cameras with the accelerometer readings and the pupil tracking from the forward-facing selfie cam, 8 can make the text you're reading compensate for the motion of the phone, so that the text appears stable and readable even when you're out running. The 8 also compensates for the distance of the phone from your eyes by increasing text size when the phone is further away. With computational reconvolution algorithms and advanced glasses-detecting computer vision techniques, the 8 can re-focus the phone screen so that no matter you're wearing your glasses or not, the 8 looks 20/20.
8 comes with an extendable screen. By using the side-mounted magnetic connectors, you can clip several 8 devices together to expand the size of your screen as far and wide as you want. The UI automatically expands to fill all available devices and switches from phone mode to tablet mode to PC mode to TV mode as the screen grows.
8 has three pico-projectors: one on the back and two in the front. The projector on the back of the phone creates an interactive tablet surface. The image is projected by the projector, and the back cameras can track your hands to make a virtual touch screen. The camera sees the color and the shape of the surface you're projecting on, automatically correcting the colors and the shape of the projection so that the image appears in the right colors and the right shape. You can use the back projector to play Kinect-style games on the wall, watch movies off the seat in front of you, display photos and documents on the meeting room desk. The front projectors track your pupils and plunge you into glassless virtual reality. The front projectors are also used to project a selfie-boosting projection field on your face that smooths out your skin, eliminates wrinkles, enlarges your eyes and slims your cheeks.
8 has 4 GB of HBM2 RAM stacked on top of a heterogenous processing die, composed of a single 4 GHz core, three 1.5 GHz cores, and 128 tiny graphics cores running at 1 GHz. The total bandwidth available for the computing cores is 256GB/s, and they can crank out 1.1 TFLOPS (single precision, ARM NEON 128-bit fused mul-add), in an address space shared between all the cores. Backing the compute cores is a two-level storage subsystem with 256 GB Flash providing 2.5 GB/s bandwidth, and a high-speed 4GB DDR pre-populated cache in front of it, serving frequently accessed data at 20 GB/s. The 8 has a lot of numbers. It comes with a worksheet-style calculator to help you manage them.
8 comes with a deep learning AI stack, used by the 8 to help manage your life. From simple things like running a spam filter on your notifications, to advanced life management techniques for building high-productive schedules, writing emails faster, researching projects and keeping you fit, the 8 puts a whole team of AI assistants at your service. With the Fake News Blocker built into the 8 browser, you won't be hoodwinked by rogue AIs and shady operators. With the 8 Scalable Helper assistant, you can provide a fully automated AI service to others and get paid for each Bit of Assistance provided.
The AI assistant team makes you a full member in today's society. With its Opinion Optimizer feature – it summons a hard-working team of virtual commenters who take your side – you can participate in online discussions as an equal opponent to other fully-armed members of the sociosphere. In case you need that extra bit of help persuading someone, the News Dreamer feature comes fully equipped with all the latest news-generating systems. Late from work? No problem! The News Dreamer can create A/B tested news stories about traffic jams and bridge closures, ready to be presented as alternative facts.
Another exciting feature of the 8 is the built-in Government app. The Government app polls you daily for your input on matters local and global. By participating in the Government, you help discover issues, find solutions for them and take part in implementing the solutions.
By buying the 8, you become a shareholder in the company that runs the Government and the Scalable Helper. As a shareholder, you'll receive a quarterly dividend from the profits generated by the company.
8 has a scan button on its side. By pressing the scan button, the camera view pops up on the screen. With the scan app, you can read QR codes, pay bills, scan business cards, save notes, translate text, see navigation directions overlaid on the view, and pull up information about the things you see. If a QR code is a link to a 3D object, the scan app loads in the object and shows it in augmented reality. You can also use the scan app to contribute information about the things that you see.
The 8 has wireless charging. Using beamforming, the charger aims a supercharged WiFi signal at the 8 with enough power to charge it. While not as fast as cable charging, the wireless charger can top the 8 to full charge in around 4 hours, and works anywhere in a 5 meter radius to the charger.
2017-01-13








































Subscribe to:
Posts (Atom)